Représenter l'unicité dans un domaine pur
Modéliser une solution à l’aide d’un domaine pur est à première vue simple à mettre en œuvre jusqu’au moment où il faut matérialiser des règles métier basées sur une collection d’entités, comme par exemple l’unicité d’une propriété.
Qu’est-ce qu’un modèle de domaine pur ?
Si on reprend la définition d’une fonction pure d’après Wikipédia :
En programmation informatique, une fonction pure est une fonction qui possède les propriétés suivantes :
- Sa valeur de retour est la même pour les mêmes arguments (pas de variation avec des variables statiques locales, des variables non locales, des arguments mutables de type référence ou des flux d’entrée).
- Son évaluation n’a pas d’effets de bord (pas de mutation de variables statiques locales, de variables non locales, d’arguments mutables de type référence ou de flux d’entrée-sortie).
Pour faire simple, une fonction pure retourne toujours le même résultat si on lui passe les mêmes arguments et ne va pas modifier un état externe quelconque (ce qui inclut l’écriture sur un volume ou une communication réseau).
Dans le cas du DDD, lorsqu’on modélise notre solution, c’est à dire qu’on crée nos entités, nos objets-valeurs, etc…, la pureté du modèle consiste principalement à ne pas appeler de services externes depuis ces objets.
Prenons un cas concret qui devrait parler à tout le monde et qui ne respecte pas cette propriété :
package auth
import "errors"
var ErrEmailShouldBeUnique = errors.New("l'email doit être unique!")
type User struct{
email string
// ... Et plein d'autres champs
}
// Abstraction de la couche de persistance
type UserRepository interface {
IsEmailUnique(email string) bool // Je simplifie et j'omet volontairement le retour des erreurs ici
// ... Et d'autres méthodes pour persister un User, le récupérer, etc...
}
func Register(repo UserRepository, email string) (*User, error) {
if !repo.IsEmailUnique(email) {
return nil, ErrEmailShouldBeUnique
}
return &User{
email: email,
}, nil
}Dans cet exemple, je souhaite faire apparaître la règle métier qui est : il ne peut y’avoir qu’un seul utilisateur par adresse mail. Comme il s’agit d’une règle métier, mon souhait est bel et bien de la représenter dans mon domaine.
Pour se faire, je demande donc en paramètre le UserRepository qui me permettra d’aller m’assurer que la condition est validée, dans le cas contraire, je retourne une erreur.
En introduisant l’appel à ce service, je casse la pureté du domaine car un effet de bord (communiquer avec la base de données ici) a été ajouté.
Si je dois tester la fonction Register, il me faudra alors implémenter un test double pour le UserRepository afin de valider les deux sorties possibles.
Le trilemme DDD
Cela dit, ce n’est pas forcément une mauvaise chose et cette solution peut tout à fait être viable !
Comme l’explique Vladimir Khorikov, il s’agit en fait d’un trilemme lorsqu’on modélise avec le DDD.
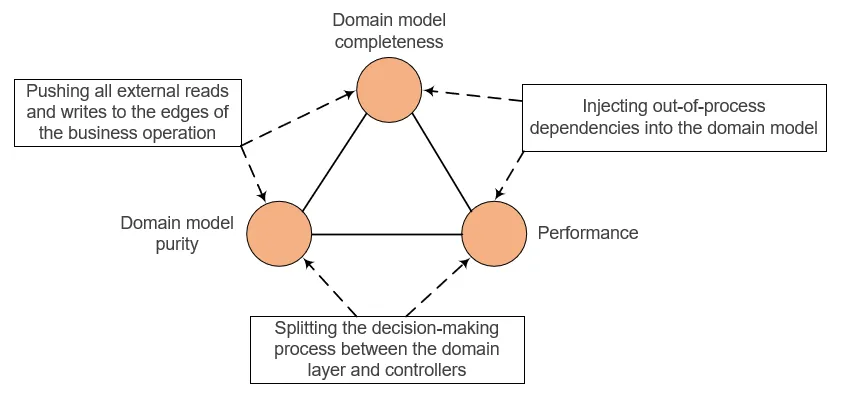
Ce trilemme met en avant 3 choix qui s’offrent à vous quand vous tentez d’utiliser le DDD pour modéliser votre solution :
- Domain model completeness : l’exhaustivité du modèle, absolument toutes les règles se trouvent dans la couche métier,
- Domain model purity : le modèle de domaine est dit pur, aucune dépendance vers des services externes (out-of-process) dans le domaine, les appels à effets de bord sont repoussés dans la couche applicative,
- Performance : il faut tout de même considérer les performances de notre modèle ce qui implique d’autres choix architecturaux.
Pour revenir sur ce dernier point, on pourrait effectivement charger toute la liste des utilisateurs de notre système, la passer en paramètre de la méthode Register et s’assurer de l’unicité de l’email. De cette manière, on écarte l’effet de bord et on rend notre fonction pure. Cela dit, on comprend très vite que d’un point de vue performance, ce serait absolument catastrophique !
// Aïe ! Imaginer avec des milliers d'utilisateurs !
func Register(email string, allUsers []*User) (*User, error) {
for _, user := range allUsers {
if user.email == email {
return nil, ErrEmailShouldBeUnique
}
}
return &User{
email: email,
}, nil
}Ce trilemme nous dit que parmi ces 3 choix, on ne peut en choisir que 2 et qu’il va donc falloir faire des compromis :
- Pousser les lectures/écritures externes en périphérie du domaine (donc plutôt dans la couche applicative), par exemple charger tout en mémoire et le passer au domaine pour valider les règles : exhaustivité et pureté,
- Injecter des dépendances de services dans le domaine : exhaustivité et performance
- Diviser la prise de décision entre la couche applicative et le domaine : pureté et performance
Et à partir de là, c’est au final à vous de choisir ce qui est le mieux selon votre pratique. Selon l’auteur, il est préférable de favoriser la pureté au détriment de l’exhaustivité (opter alors pour la troisième approche) et de mon côté, je partage plutôt cet avis. Partir sur un modèle plus simple est toujours une bonne chose et vous permet de tester aisément des cas complexes.
Pureté et performance, comment retrouver un peu d’exhaustivité ?
Si j’écris cet article c’est justement car j’ai été confronté à ce choix sur seelf. Depuis le début, j’avais choisi de partir sur un domaine aussi pur que possible pour faciliter la testabilité de l’application.
Seulement, mettre de côté l’exhaustivité du modèle ne me satisfaisait pas vraiment. En lisant les commentaires de l’article cité plus haut, on s’aperçoit qu’on peut rétablir un peu d’exhaustivité y compris en optant pour un modèle pur. Par exemple, si je reprends le code précédent :
func Register(email string, unique bool) (*User, error) {
if !unique {
return nil, ErrEmailShouldBeUnique
}
return &User{
email: email,
}, nil
}En introduisant le booléen unique, on a repoussé la récupération de cette information dans la couche applicative (via la méthode UserRepository.IsEmailUnique) pour préserver un modèle pur et simple dans notre couche métier. De cette manière, on rétablit une partie de l’exhaustivité qu’on a concédé via notre choix.
On peut aller encore un peu plus loin en définissant un nouveau type qui éliminera les ambiguïtés restantes :
type EmailAvailability bool // On définit un nouveau type
type UserRepository interface {
GetEmailAvailability(email string) EmailAvailability
}
func Register(email string, available EmailAvailability) (*User, error) {
if !available {
return nil, ErrEmailShouldBeUnique
}
return &User{
email: email,
}, nil
}De cette manière, à la lecture de la signature de la méthode, on comprend très vite ce qui se passe. Les tests restent extrêmement simples car il suffit de passer true ou false en paramètre et de vérifier les retours. Côté performance, on ne perd rien car c’est l’implémentation du UserRepository qui aura la charge de vérifier l’unicité (via un COUNT si SQL par exemple) et niveau exhaustivité, on conserve une part non négligeable de l’intention originale.
Parfois, les choses sont encore plus compliquées et la règle métier repose sur plusieurs informations que seule la collection d’entités possède.
Dans ce cas, on peut avoir recours à des types plus complexes qu’un simple booléen. Par exemple sur seelf, dans la prochaine version, on pourra déployer des applications sur des instances Docker distantes. L’unicité du nom d’une application est donc fonction du nom de l’application et des différentes cibles configurées. Pour représenter cette complexité, j’ai décidé d’utiliser un bitmask :
type AppNamingAvailability uint8
const (
AppNamingProductionTargetNotFound AppNamingAvailability = 1 << iota
AppNamingStagingTargetNotFound
AppNamingTakenInProduction
AppNamingTakenInStaging
AppNamingAvailable
)
type AppsReader interface {
GetAppNamingAvailability(context.Context, AppName, TargetID, TargetID) (AppNamingAvailability, error)
// ...
}
func NewApp(
name AppName,
production EnvironmentConfig,
staging EnvironmentConfig,
createdBy domain.UserID,
available AppNamingAvailability,
) (app App, err error) {
if available != AppNamingAvailable {
return app, ErrInvalidAppNaming
}
// ...
}
// Dans la couche applicative, j'utilise `AppsReader.GetAppNamingAvailability`
// et je peux alors retourner une erreur précise à l'utilisateur suivant les
// valeurs du masque.Grâce à ce bitmask, j’ai la possibilité de savoir pour quelle raison le nom n’est pas disponible ce qui me permet de retourner une erreur plus précise à l’utilisateur au niveau de la couche applicative.
Cette solution n’est évidemment pas parfaite mais permet tout de même de limiter les concessions sur l’exhaustivité du modèle alors pensez-y 😉 !